忍法:声音克隆之术-GPT-sovits
声音克隆
前言:
最近因为一直在给肚子里面的宝宝做故事胎教,每天(其实是看自己心情抽空讲下故事)都要给宝宝讲故事,心想反正宝宝也看不见我,只听我的声音,干脆偷个懒,克隆自己的声音,然后把故事输入进去。然后老婆想给宝宝做胎教的时候就可以输入一个故事,即使我还没下班也可以给宝宝讲故事,岂不美哉!果然,偷懒是人类进步的阶梯,说干就干。我找了一圈相应的软件,发现GPT-sovits非常符合我的需求,又是开源的,又不需要很长时间的音频素材,简直完美,所以就有了下面的GPT-vosits使用教程。其实网上已经有很多这样的教程了,大家都可以搜一搜,我也只是记录一下自己的使用过程,顺便水(记录)一篇博客,好久没写了,感觉还是的写一写,要不然真的是浪费了自己空闲时间。
使用:
前置条件:
测试通过的环境
下面这个摘自官网,需要用python环境,最好是有一张好的显卡,没有的话cpu其实也可以跑,就是慢嘛。
- Python 3.9,PyTorch 2.0.1,CUDA 11
- Python 3.10.13,PyTorch 2.1.2,CUDA 12.3
- Python 3.9,Pytorch 2.2.2,macOS 14.4.1(Apple 芯片)
- Python 3.9,PyTorch 2.2.2,CPU 设备
注: numba==0.56.4 需要 python<3.11
因为我这个纯粹是给自己使用,也就没有折腾在云上,或者服务器上的使用操作了。只有windows电脑的使用步骤,如果各位读者是会点编程,有技术背景的话,可以看下最底部的参考资料,里面有官网的语雀文档,里面有介绍怎么在云上使用,linux,macOS使用等情况。
1.从官网下载
官网上提供了两个整合包,0206fix3 整合包或0217fix2 整合包,但是都是huggingface(国外的)下载会很慢。
还有一个方式就是去B站关注下up主:花儿不哭,自动回复消息里面会有连接。这里我提供了花儿不哭大佬给的网盘地址,下载地址,不过还是建议各位去关注一下一键三连,为大佬的开源精神支持一下。
2.下载完之后,解压7z格式的文件
3.双击go-webui.bat
4.语音处理
如果你的音频素材,很干净,比如说就是你手机录的你自己的声音,那可以跳过这一步。
如果你的素材是从网上下载过来的,里面有背景声音,杂音等,那就需要走这一步,这样分离出来的声音效果更好,后续输出声音才会更加准确。
4.1
我这里是从网上下载的一个海绵宝宝的声音素材,里面有背景音,所以我需要先处理下音频文件,勾选是否开启UVR5-WebUI的勾选框,会弹出来一个新的界面。
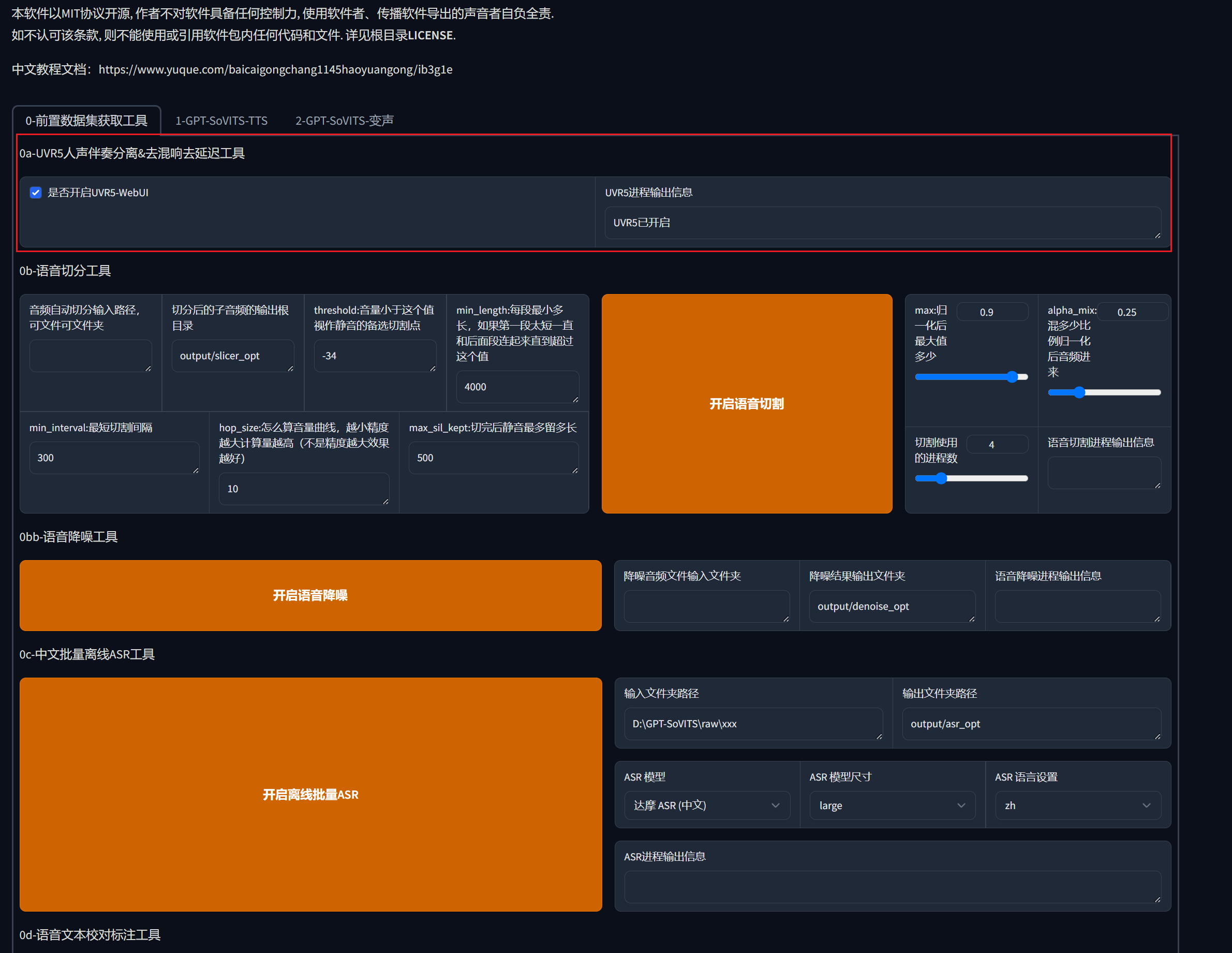
4.2
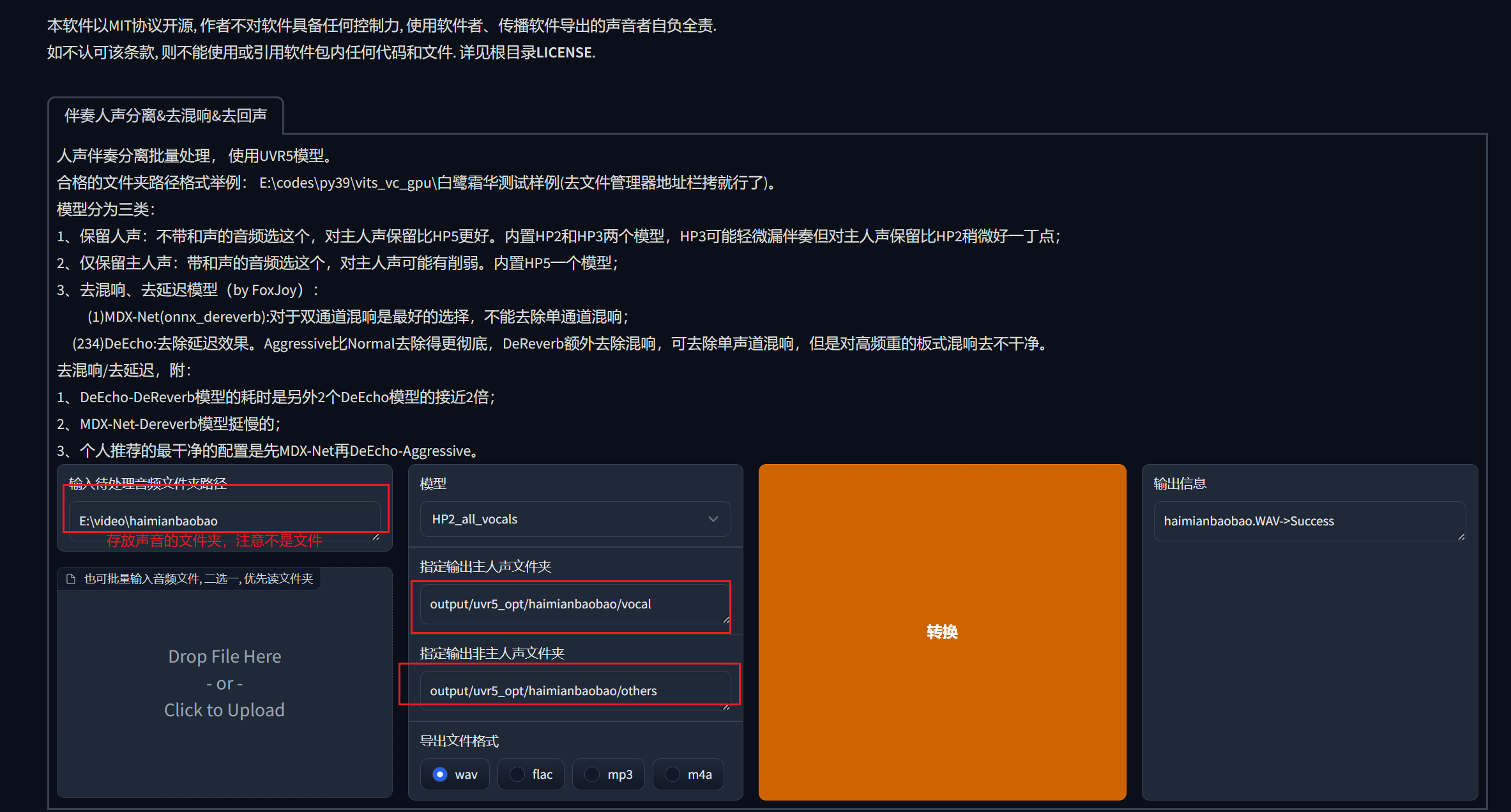
参考下面的图,把音频文件放到某个目录,举例,我这里把海绵宝宝的声音放到E:\video\haimianbaobao里面,
然后在下面的第一个红框里面填入文件系统的地址。红框下面那个是可以直接拖入文件的,也可以用下面那个。
接着,填写输出__主人声的文件夹__,比如我的音频文件里面不是有海绵宝宝的声音和背景音吗,海绵宝宝的声音就是主人声,其他的声音都是用不到的,就填写在__非主人声文件夹__里面。这里我特意区分了一下,写了一个vocal(主人声)和others(非主人声)的路径,这个路径不存在也没关系,点击转换之后软件会自动创建文件夹。
5.语音切分
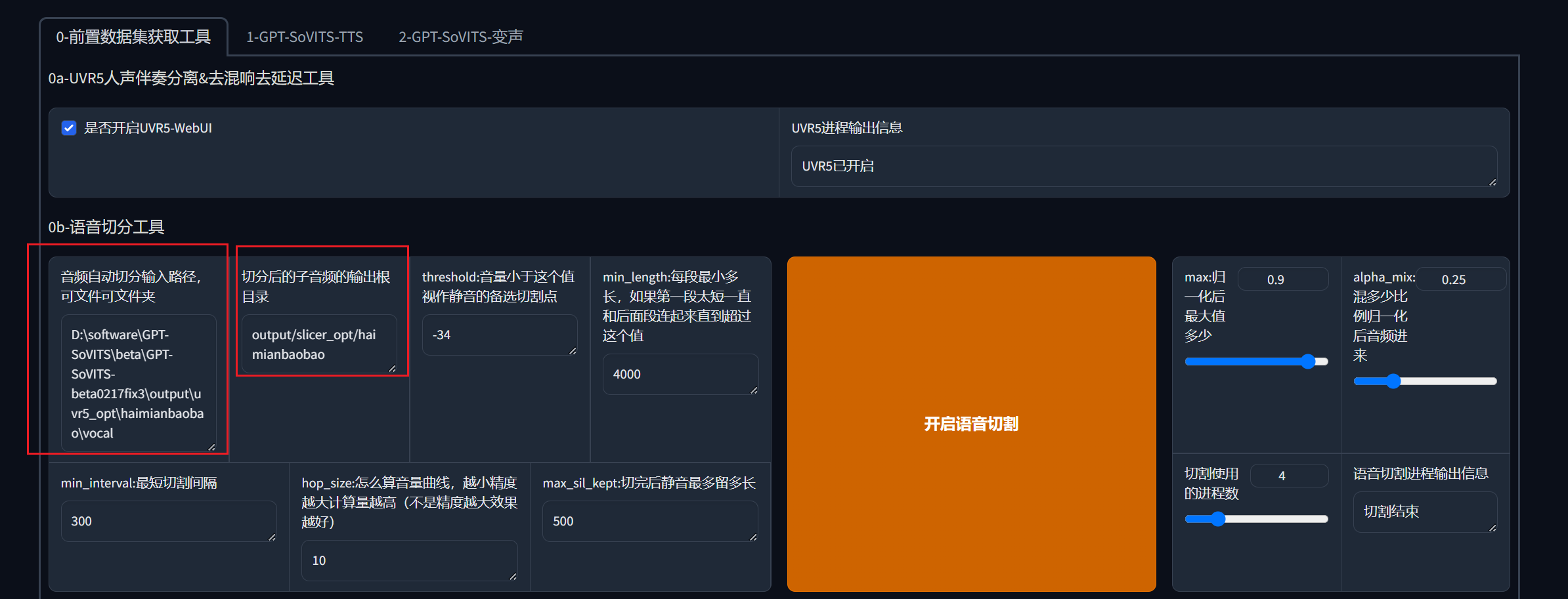
因为这个语音很长的话,训练效果会很差,所以需要将长的语音切短。不过我们这里用的声音其实挺短的,只有10秒,所以只切出来一个文件,如果是比较完整的素材效果会更加好,官网是这么说的如果你的显卡有24G显存,那么高于24秒的音频就要去掉,可以参考一下,看看自己的电脑配置去掉过长的音频。将上一步处理完的音频文件/文件夹地址粘贴过来放到第一个红框里面,然后第二个红框加上/haimianbaobao方便和其他音频文件区分开。
6.语音降噪
官网说这个功能不太好用,慎用,所以我们就不用这个功能了,直接跳过

7.语音打标
输入上一步得到的文件夹地址,然后填入输出文件夹路径,我们依然是加一个haimianbaobao的文件夹
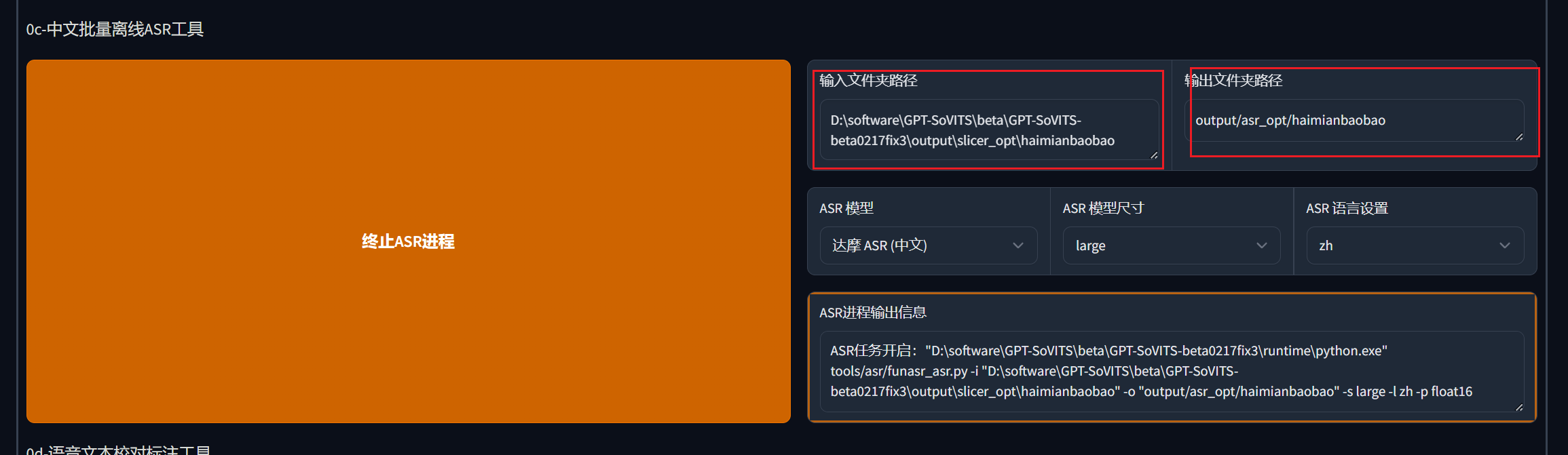
8.校对标注
一般这个标注都是准的,可能有些多音字,或者词语可能会标错之类的,填写好标注文件的地址,开启标注WebUI进行修改调整。我们这里就一句话,也没啥好调的直接跳过了


9.训练模型
切换到第二个TTS的界面,填入标注文件地址,切分文件目录,在点击一键三连即可。
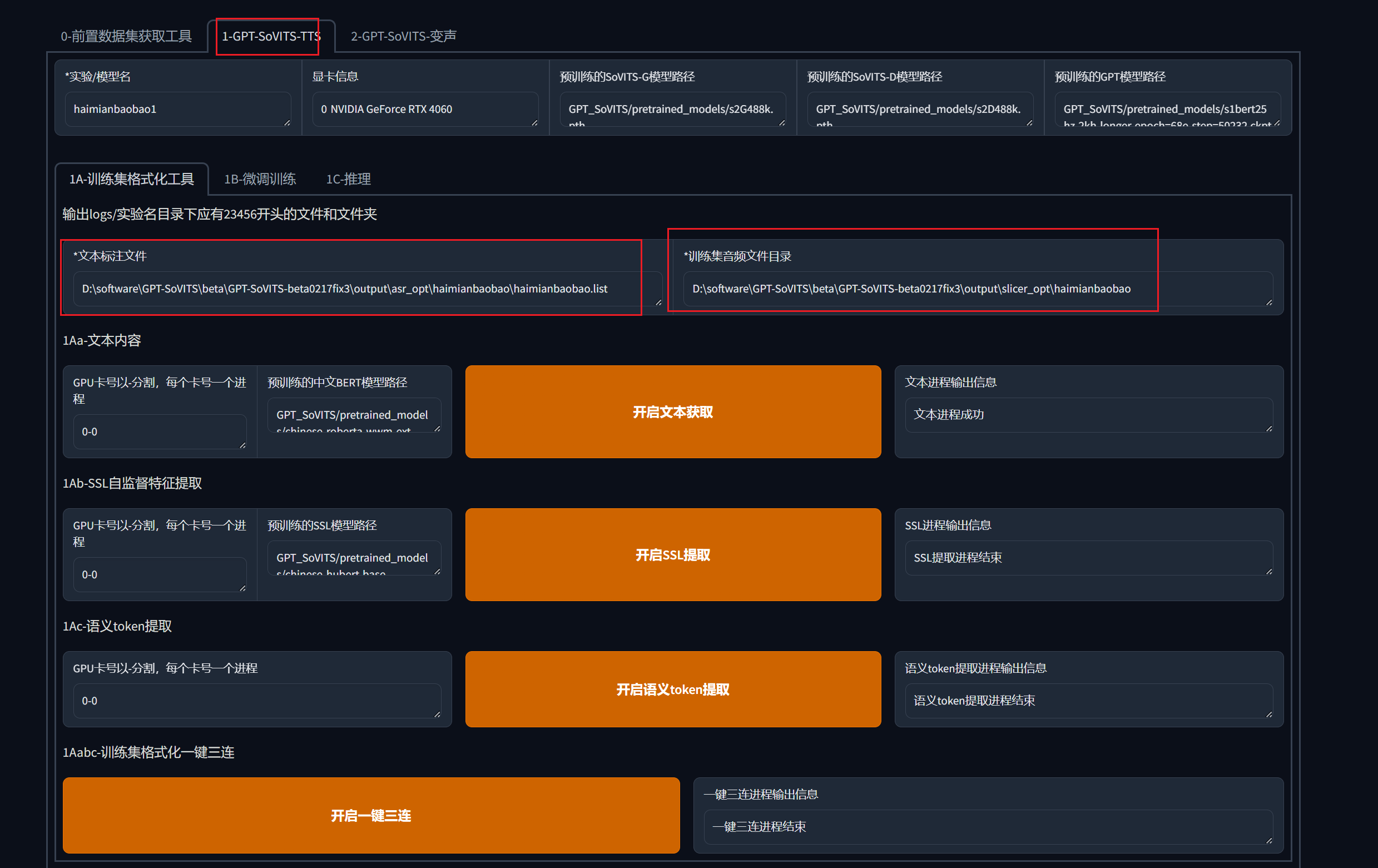
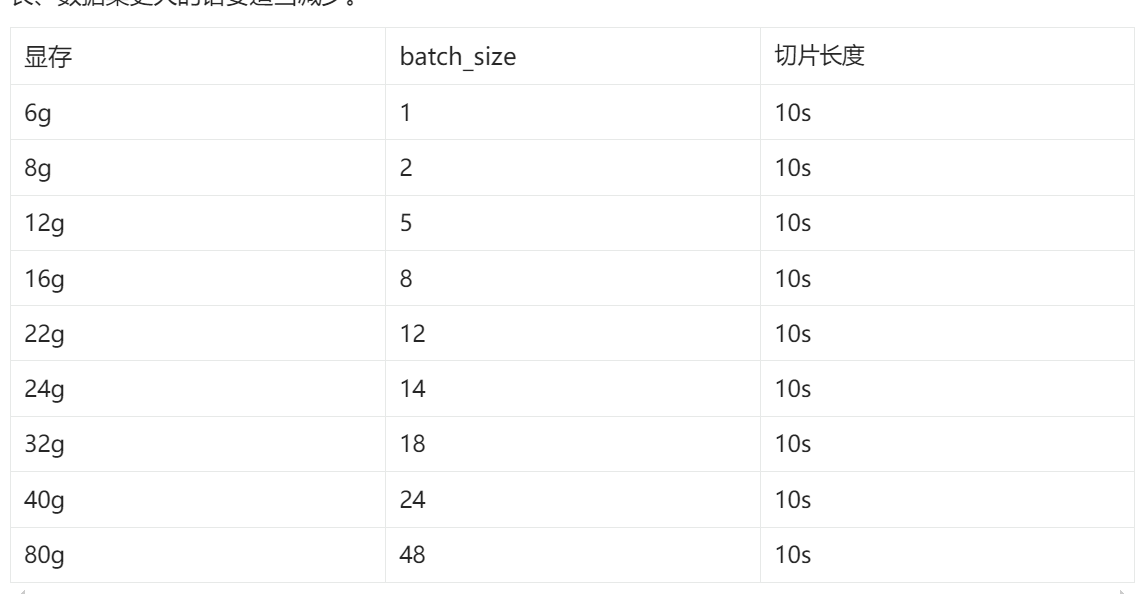
10.微调训练
微调训练反正根据自己的显卡来,我这里是一张8G的4060,batch_size都选的2,两个训练,SoVITS,GPT依次训练过来。训练轮次在显卡显存不太大的时候也调小一点。
11.推理
以上的步骤都弄完了,恭喜你,已经可以愉快的玩耍了。
点到推理的栏目,选择自己之前训练的模型,你可能会看到haimianbaobao的模型有好几个,还有类似e10这样的后缀,表示它的训练轮次,你可以几个模型都试一下哪个效果最好,就用哪个。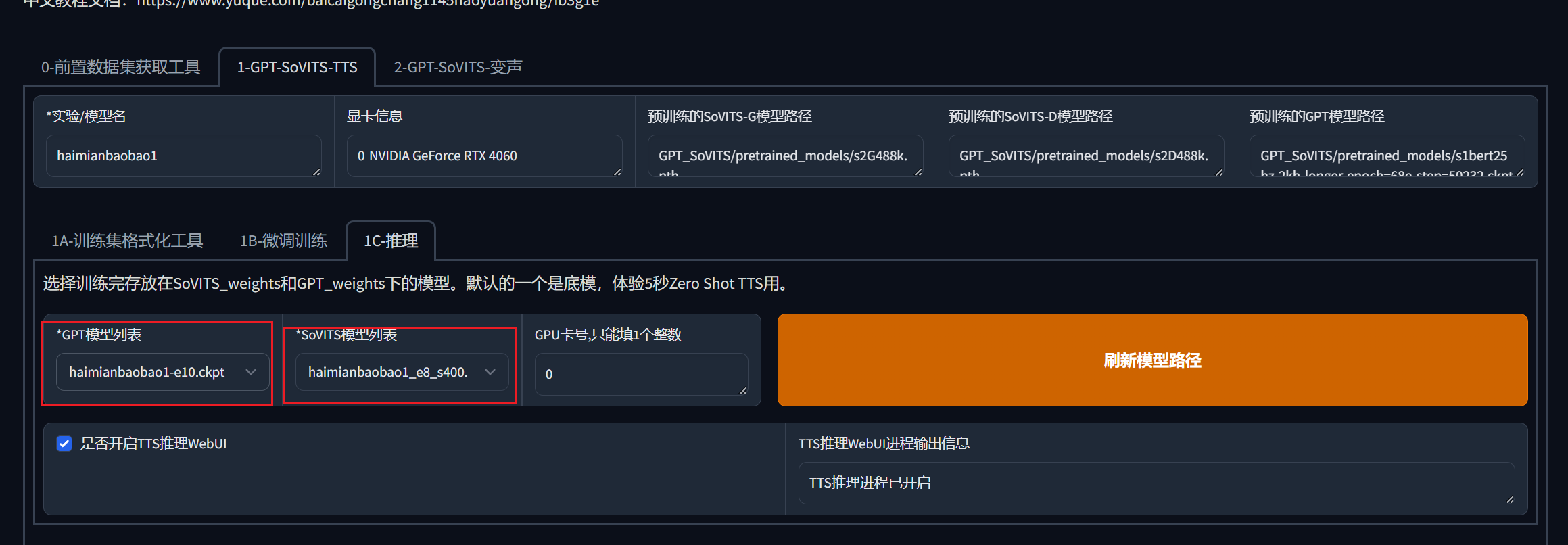
如果没有看到你训练的模型,点击刷新模型路径试试。
之后再勾选开启TTS推理WebUI,跳转到一个新的界面,然后在输入一段3-10秒参考音频,我们就从切分好的音频文件夹/slicer_opt/haimianbaobao里面选一个长度符合的即可。
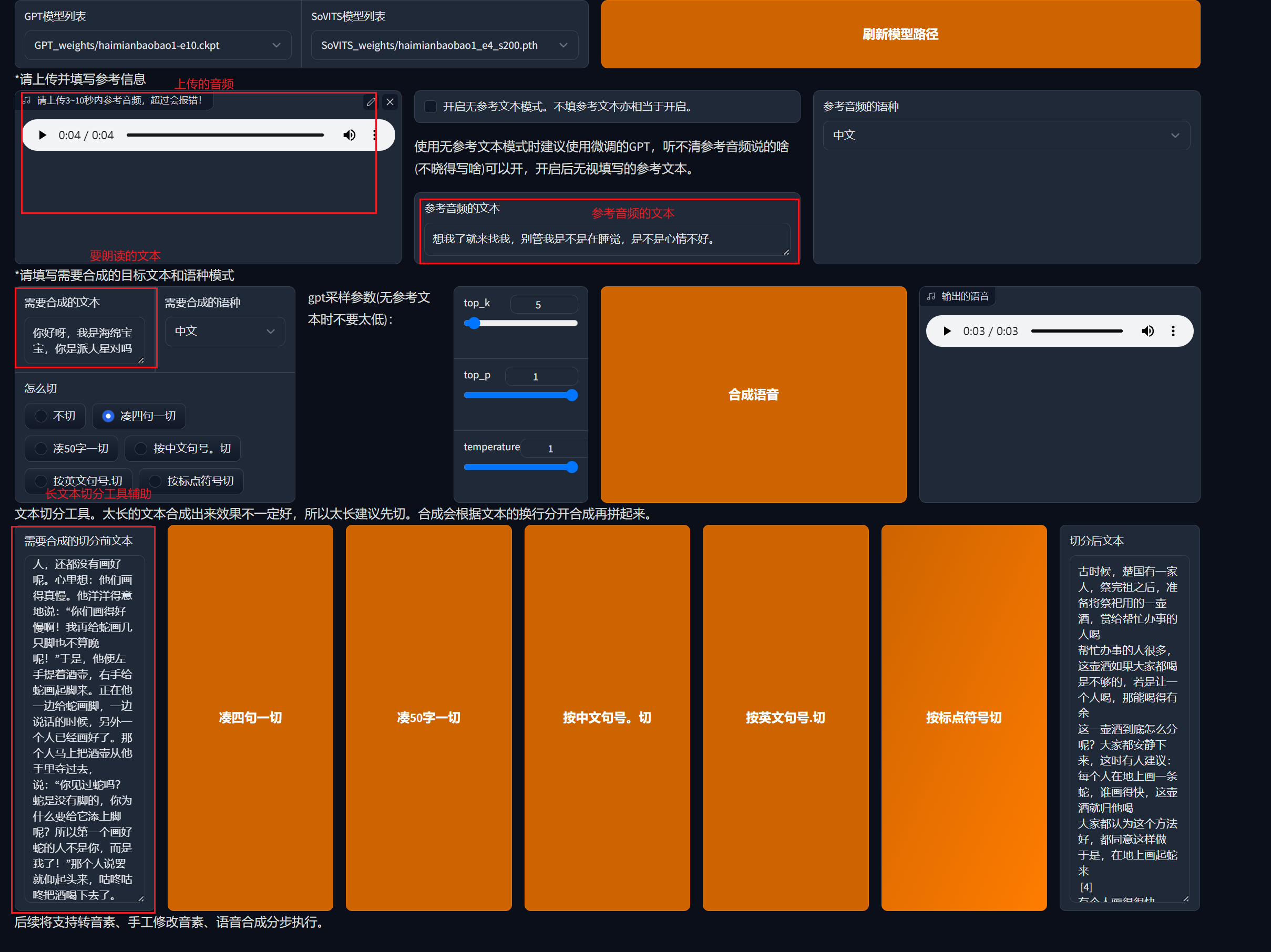
接着在输入你想要朗读的文本,点击推理,就会生成一个音频文件,就可以听到你训练的声音读的文本啦~
如果你的文本很长,下面还会有一个辅助长文本切分的工具,可以按照好几种方式切分,然后把在切分好的文本放入到要合成的文本里面。
后记
训练了自己的声音,以为可以偷懒用软件替代自己给宝宝讲故事了,结果老婆嫌弃软件没有我讲的声情并茂,也没用几次,还是要我自己讲故事。呜呼,白搞。整体从训练过程来看还是比较麻烦的,对于有技术背景的人可能还好,对于小白来说还是比较复杂的,参考资料里面有个UP主对GPT-SoVITs的流程进行了简化,有兴趣的也可以看看。